History of statistics
| History of science |
|---|
|
Background
|
|
|
|
|
|
Navigational pages
|
The history of statistics can be said to start around 1749 although, over time, there have been changes to the interpretation of what the word statistics means. In early times, the meaning was restricted to information about states. This was later extended to include all collections of information of all types, and later still it was extended to include the analysis and interpretation of such data. In modern terms, "statistics" means both sets of collected information, as in national accounts and temperature records, and analytical work which requires statistical inference.
Statistical activities are often associated with models expressed using probabilities, and require probability theory for them to be put on a firm theoretical basis: see History of probability.
A number of statistical concepts have had an important impact on a wide range of sciences. These include the design of experiments and approaches to statistical inference such as Bayesian inference, each of which can be considered to have their own sequence in the development of the ideas underlying modern statistics.
Contents |
Introduction
By the 18th century, the term "statistics" designated the systematic collection of demographic and economic data by states. In the early 19th century, the meaning of "statistics" broadened, then including the discipline concerned with the collection, summary, and analysis of data. Today statistics is widely employed in government, business, and all the sciences. Electronic computers have expedited statistical computation, and have allowed statisticians to develop "computer-intensive" methods.
The term "mathematical statistics" designates the mathematical theories of probability and statistical inference, which are used in statistical practice. The relation between statistics and probability theory developed rather late, however. In the 19th century, statistics increasingly used probability theory, whose initial results were found in the 17th and 18th centuries, particularly in the analysis of games of chance (gambling). By 1800, astronomy used probability models and statistical theories, particularly the method of least squares, which was invented by Legendre and Gauss. Early probability theory and statistics was systematized and extended by Laplace; following Laplace, probability and statistics have been in continual development. In the 19th century, social scientists used statistical reasoning and probability models to advance the new sciences of experimental psychology and sociology; physical scientists used statistical reasoning and probability models to advance the new sciences of thermodynamics and statistical mechanics. The development of statistical reasoning was closely associated with the development of inductive logic and the scientific method.
Statistics is not a field of mathematics but an autonomous mathematical science, like computer science or operations research. Unlike mathematics, statistics had its origins in public administration and maintains a special concern with demography and economics. Being concerned with the scientific method and inductive logic, statistical theory has close association with the philosophy of science; with its emphasis on learning from data and making best predictions, statistics has great overlap with the decision science and microeconomics. With its concerns with data, statistics has overlap with information science and computer science.
Etymology
- Look up statistics in wiktionary, the free dictionary.
The term statistics is ultimately derived from the New Latin statisticum collegium ("council of state") and the Italian word statista ("statesman" or "politician"). The German Statistik, first introduced by Gottfried Achenwall (1749), originally designated the analysis of data about the state, signifying the "science of state" (then called political arithmetic in English). It acquired the meaning of the collection and classification of data generally in the early 19th century. It was introduced into English in 1791 by Sir John Sinclair when he published the first of 21 volumes titled Statistical Account of Scotland.[1]
Thus, the original principal purpose of Statistik was data to be used by governmental and (often centralized) administrative bodies. The collection of data about states and localities continues, largely through national and international statistical services. In particular, censuses provide regular information about the population.
The first book to have 'statistics' in its title was "Contributions to Vital Statistics" by Francis GP Neison, actuary to the Medical Invalid and General Life Office (1st ed., 1845; 2nd ed., 1846; 3rd ed., 1857).
Origins in probability
The earliest writing on statistics was found in a 9th century book entitled: "Manuscript on Deciphering Cryptographic Messages", written by Al-Kindi (801–873 AC). In his book, Al-Kindi gave a detailed description of how to use statistics and frequency analysis to decipher encrypted messages, this was the birth of both statistics and cryptanalysis[2][3].
The "Nuova Cronica", a 14th century history of Florence by the Florentine banker and official Giovanni Villani, includes many statistical information on population, ordinances, commerce and trade, education, and religious facilities and has been described as the first introduction of statistics as a positive element in history,[4] though neither the term nor the concept of statistics as a specific field yet existed. But this was proven to be incorrect after the rediscovery of Al-Kindi's book on frequency analysis[2][3].
The mathematical methods of statistics emerged from probability theory, which can be dated to the correspondence of Pierre de Fermat and Blaise Pascal (1654). Christiaan Huygens (1657) gave the earliest known scientific treatment of the subject. Jakob Bernoulli's Ars Conjectandi (posthumous, 1713) and Abraham de Moivre's The Doctrine of Chances (1718) treated the subject as a branch of mathematics. See Ian Hacking's The Emergence of Probability and James Franklin's The Science of Conjecture: Evidence and Probability Before Pascal for histories of the early development of the very concept of mathematical probability. In the modern era, the work of Kolmogorov has been instrumental in formulating the fundamental model of Probability Theory, which is used throughout statistics.
The theory of errors may be traced back to Roger Cotes' Opera Miscellanea (posthumous, 1722), but a memoir prepared by Thomas Simpson in 1755 (printed 1756) first applied the theory to the discussion of errors of observation. The reprint (1757) of this memoir lays down the axioms that positive and negative errors are equally probable, and that there are certain assignable limits within which all errors may be supposed to fall; continuous errors are discussed and a probability curve is given.
Pierre-Simon Laplace (1774) made the first attempt to deduce a rule for the combination of observations from the principles of the theory of probabilities. He represented the law of probability of errors by a curve. He deduced a formula for the mean of three observations. He also gave (1781) a formula for the law of facility of error (a term due to Joseph Louis Lagrange, 1774), but one which led to unmanageable equations. Daniel Bernoulli (1778) introduced the principle of the maximum product of the probabilities of a system of concurrent errors.
The method of least squares, which was used to minimize errors in data measurement, was published independently by Adrien-Marie Legendre (1805), Robert Adrain (1808), and Carl Friedrich Gauss (1809). Gauss had used the method in his famous 1801 prediction of the location of the dwarf planet Ceres. Further proofs were given by Laplace (1810, 1812), Gauss (1823), Ivory (1825, 1826), Hagen (1837), Bessel (1838), Donkin (1844, 1856), Herschel (1850), Crofton (1870), and Thiele (1880, 1889).
Other contributors were Ellis (1844), De Morgan (1864), Glaisher (1872), and Giovanni Schiaparelli (1875). Peters's (1856) formula for 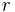 , the "probable error" of a single observation was widely used and inspired early robust statistics (resistant to outliers).
, the "probable error" of a single observation was widely used and inspired early robust statistics (resistant to outliers).
In the 19th century authors on statistical theory included Laplace, S. Lacroix (1816), Littrow (1833), Dedekind (1860), Helmert (1872), Laurant (1873), Liagre, Didion, De Morgan, Boole, Edgeworth, and K. Pearson.
Adolphe Quetelet (1796–1874), another important founder of statistics, introduced the notion of the "average man" (l'homme moyen) as a means of understanding complex social phenomena such as crime rates, marriage rates, or suicide rates.
Design of experiments
In 1747, while serving as surgeon on HM Bark Salisbury, James Lind carried out a controlled experiment to develop a cure for scurvy.[5] In this study his subjects' cases "were as similar as I could have them", that is he provided strict entry requirements to reduce extraneous variation. The men were paired, which provided blocking. From a modern perspective, the main thing that is missing is randomized allocation of subjects to treatments.
A theory of statistical inference was developed by Charles S. Peirce in "Illustrations of the Logic of Science" (1877–1878) and "A Theory of Probable Inference" (1883), two publications that emphasized the importance of randomization-based inference in statistics.
In another study, Peirce randomly assigned volunteers to a blinded, repeated-measures design to evaluate their ability to discriminate weights.[6][7][8][9] Peirce's experiment inspired other researchers in psychology and education, which developed a research tradition of randomized experiments in laboratories and specialized textbooks in the 1800s.[6][7][8][9]
Charles S. Peirce also contributed the first English-language publication on an optimal design for regression-models in 1876.[10] A pioneering optimal design for polynomial regression was suggested by Gergonne in 1815. In 1918 Kirstine Smith published optimal designs for polynomials of degree six (and less).
The use of a sequence of experiments, where the design of each may depend on the results of previous experiments, including the possible decision to stop experimenting, was pioneered[11] by Abraham Wald in the context of sequential tests of statistical hypotheses.[12] Herman Chernoff wrote an overview of optimal sequential designs,[13] while adaptive designs have been surveyed by S. Zacks.[14] One specific type of sequential design is the "two-armed bandit", generalized to the multi-armed bandit, on which early work was done by Herbert Robbins in 1952.[15]
A methodology for designing experiments was proposed by Ronald A. Fisher, in his innovative book The Design of Experiments (1935). As an example, he described how to test the hypothesis that a certain lady could distinguish by flavour alone whether the milk or the tea was first placed in the cup. While this sounds like a frivolous application, it allowed him to illustrate the most important ideas of experimental design: see Lady tasting tea.
Inference
Charles S. Peirce (1839—1914) formulated frequentist theories of estimation and hypothesis-testing in (1877—1878) and (1883), in which he introduced "confidence". Peirce also introduced blinded, controlled randomized experiments with a repeated measures design.[16] Peirce invented an optimal design for experiments on gravity.
Bayesian statistics
The term Bayesian refers to Thomas Bayes (1702–1761), who proved a special case of what is now called Bayes' theorem. However, it was Pierre-Simon Laplace (1749–1827) who introduced a general version of the theorem and used it to approach problems in celestial mechanics, medical statistics, reliability, and jurisprudence.[17] When insufficient knowledge was available to specify an informed prior, Laplace used uniform priors, according to his "principle of insufficient reason".[18] Laplace also introduced primitive versions of conjugate priors and the theorem of von Mises and Bernstein, according to which the posteriors corresponding to initially differing priors ultimately agree, as the number of observations increases.[19] This early Bayesian inference, which used uniform priors following Laplace's principle of insufficient reason, was called "inverse probability" (because it infers backwards from observations to parameters, or from effects to causes [20]).
After the 1920s, inverse probability was largely supplanted by a collection of methods that were developed by Ronald A. Fisher, Jerzy Neyman and Egon Pearson. Their methods came to be called frequentist statistics.[20] Fisher rejected the Bayesian view, writing that "the theory of inverse probability is founded upon an error, and must be wholly rejected" .[21] At the end of his life, however, Fisher expressed greater respect for the essay of Bayes, which Fisher believed to have anticipated his own, fiducial approach to probability; Fisher still maintained that Laplace's views on probability were "fallacious rubbish".[21] Neyman started out as a "quasi-Bayesian", but subsequently developed confidence intervals (a key method in frequentist statistics) because "the whole theory would look nicer if it were built from the start without reference to Bayesianism and priors".[22] The word Bayesian appeared in the 1930s, and by the 1960s it became the term preferred by those dissatisfied with the limitations of frequentist statistics.[20][23]
In the 20th century, the ideas of Laplace were further developed in two different directions, giving rise to objective and subjective currents in Bayesian practice. In the objectivist stream, the statistical analysis depends on only the model assumed and the data analysed.[24] No subjective decisions need to be involved. In contrast, "subjectivist" statisticians deny the possibility of fully objective analysis for the general case.
In the further development of Laplace's ideas, subjective ideas predate objectivist positions. The idea that 'probability' should be interpreted as 'subjective degree of belief in a proposition' was proposed, for example, by John Maynard Keynes in the early 1920s. This idea was taken further by Bruno de Finetti in Italy (Fondamenti Logici del Ragionamento Probabilistico, 1930) and Frank Ramsey in Cambridge (The Foundations of Mathematics, 1931).[25] The approach was devised to solve problems with the frequentist definition of probability but also with the earlier, objectivist approach of Laplace.[24] The subjective Bayesian methods were further developed and popularized in the 1950s by L.J. Savage.
Objective Bayesian inference was further developed due to Harold Jeffreys, whose seminal book "Theory of probability" first appeared in 1939. In 1957, Edwin Jaynes promoted the concept of maximum entropy for constructing priors, which is an important principle in the formulation of objective methods, mainly for discrete problems. In 1965, Dennis Lindley's 2-volume work "Introduction to Probability and Statistics from a Bayesian Viewpoint" brought Bayesian methods to a wide audience. In 1979, José-Miguel Bernardo introduced reference analysis,[24] which offers a general applicable framework for objective analysis. Other well-known proponents of Bayesian probability theory include I.J. Good, B.O. Koopman, Howard Raiffa, Robert Schlaifer and Alan Turing.
In the 1980s, there was a dramatic growth in research and applications of Bayesian methods, mostly attributed to the discovery of Markov chain Monte Carlo methods, which removed many of the computational problems, and an increasing interest in nonstandard, complex applications.[26] Despite growth of Bayesian research, most undergraduate teaching is still based on frequentist statistics.[27] Nonetheless, Bayesian methods are widely accepted and used, such as for example in the field of machine learning.[28]
Statistics today
During the 20th century, the creation of precise instruments for agricultural research, public health concerns (epidemiology, biostatistics, etc.), industrial quality control, and economic and social purposes (unemployment rate, econometry, etc.) necessitated substantial advances in statistical practices.
Today the use of statistics has broadened far beyond its origins. Individuals and organizations use statistics to understand data and make informed decisions throughout the natural and social sciences, medicine, business, and other areas.
Statistics is generally regarded not as a subfield of mathematics but rather as a distinct, albeit allied, field. Many universities maintain separate mathematics and statistics departments. Statistics is also taught in departments as diverse as psychology, education, and public health.
Important contributors to statistics
- Thomas Bayes
- George E. P. Box
- Pafnuty Chebyshev
- David R. Cox
- Gertrude Cox
- Harald Cramér
- Francis Ysidro Edgeworth
- Bradley Efron
- Bruno de Finetti
- Ronald A. Fisher
- Francis Galton
- Carl Friedrich Gauss
- William Sealey Gosset (“Student”)
- Andrey Kolmogorov
- Pierre-Simon Laplace
- Erich L. Lehmann
- Aleksandr Lyapunov
- Abraham De Moivre
- Jerzy Neyman
- Florence Nightingale
- Blaise Pascal
- Karl Pearson
- Charles S. Peirce
- Adolphe Quetelet
- C. R. Rao
- Walter A. Shewhart
- Charles Spearman
- Thorvald N. Thiele
- John Tukey
- Abraham Wald
References
- ^ Ball, Philip (2004). Critical Mass. Farrar, Straus and Giroux. p. 53. ISBN 0374530416.
- ^ a b Singh, Simon (2000). The code book : the science of secrecy from ancient Egypt to quantum cryptography (1st Anchor Books ed. ed.). New York: Anchor Books. ISBN 0385495323.
- ^ a b Ibrahim A. Al-Kadi "The origins of cryptology: The Arab contributions”, Cryptologia, 16(2) (April 1992) pp. 97–126.
- ^ Villani, Giovanni. Encyclopædia Britannica. Encyclopædia Britannica 2006 Ultimate Reference Suite DVD. Retrieved on 2008-03-04.
- ^ Dunn, Peter (January 1997). "James Lind (1716-94) of Edinburgh and the treatment of scurvy". Archive of Disease in Childhood Foetal Neonatal (United Kingdom: British Medical Journal Publishing Group) 76 (1): 64–65. doi:10.1136/fn.76.1.F64. PMC 1720613. PMID 9059193. http://fn.bmj.com/cgi/content/full/76/1/F64. Retrieved 2009-01-17.
- ^ a b Charles Sanders Peirce and Joseph Jastrow (1885). "On Small Differences in Sensation". Memoirs of the National Academy of Sciences 3: pp. 73–83. http://psychclassics.yorku.ca/Peirce/small-diffs.htm.
- ^ a b Hacking, Ian (September 1988). "Telepathy: Origins of Randomization in Experimental Design". Isis 79 (A Special Issue on Artifact and Experiment): pp. 427–451. JSTOR 234674. MR1013489.
- ^ a b Stephen M. Stigler (November 1992). "A Historical View of Statistical Concepts in Psychology and Educational Research". American Journal of Education 101 (1): pp. 60–70.
- ^ a b Trudy Dehue (December 1997). "Deception, Efficiency, and Random Groups: Psychology and the Gradual Origination of the Random Group Design". Isis 88 (4): pp. 653–673.
- ^ Peirce, C. S. (1876). "Note on the Theory of the Economy of Research". Coast Survey Report: pp. 197–201., actually published 1879, NOAA PDF Eprint.
Reprinted in Collected Papers 7, paragraphs 139–157, also in Writings 4, pp. 72–78, and in Peirce, C. S. (July–August 1967). "Note on the Theory of the Economy of Research". Operations Research 15 (4): pp. 643–648. doi:10.1287/opre.15.4.643. JSTOR 168276. - ^ Johnson, N.L. (1961). "Sequential analysis: a survey." Journal of the Royal Statistical Society, Series A. Vol. 124 (3), 372–411. (pages 375–376)
- ^ Wald, A. (1945) "Sequential Tests of Statistical Hypotheses", Annals of Mathematical Statistics, 16 (2), 117–186.
- ^ Chernoff, H. (1972) Sequential Analysis and Optimal Design, SIAM Monograph
- ^ Zacks, S. (1996) "Adaptive Designs for Parametric Models". In: Ghosh, S. and Rao, C. R., (Eds) (1996). "Design and Analysis of Experiments," Handbook of Statistics, Volume 13. North-Holland. ISBN 0-444-82061-2. (pages 151–180)
- ^ Robbins, H. (1952). "Some Aspects of the Sequential Design of Experiments". Bulletin of the American Mathematical Society 58 (5): 527–535. doi:10.1090/S0002-9904-1952-09620-8.
- ^ Hacking, Ian (September 1988). "Telepathy: Origins of Randomization in Experimental Design". Isis 79 (A Special Issue on Artifact and Experiment): 427–451. doi:10.1086/354775. JSTOR 234674. MR1013489.
- ^ Sigler (1990, Chapter 3)
- ^ Hald (1998), Stigler (1990)
- ^ Lucien Le Cam (1986) Asymptotic Methods in Statistical Decision Theory: Pages 336 and 618–621 (von Mises and Bernstein).
- ^ a b c Stephen. E. Fienberg, (2006) When did Bayesian Inference become "Bayesian"? Bayesian Analysis, 1 (1), 1–40. See page 5.
- ^ a b Aldrich, A., R. A. Fisher on Bayes and Bayes' Theorem, Bayesian analysis (2008), 3, number 1, pp. 161–170
- ^ Neyman, J. (1977). "Frequentist probability and frequentist statistics". Synthese 36 (1): 97–131. doi:10.1007/BF00485695.
- ^ Jeff Miller, "Earliest Known Uses of Some of the Words of Mathematics (B)"
- ^ a b c Bernardo JM. (2005). "Reference analysis". Handbook of statistics 25: 17–90. doi:10.1016/S0169-7161(05)25002-2.
- ^ Gillies, D. (2000), Philosophical Theories of Probability. Routledge. ISBN 041518276X pp 50–1
- ^ Wolpert, RL. (2004) A conversation with James O. Berger, Statistical science, 9, 205–218
- ^ José M. Bernardo (2006) A Bayesian mathematical statistics primer. ICOTS-7
- ^ Bishop, C.M. (2007) Pattern Recognition and Machine Learning. Springer, 2007
Bibliography
- Hald, Anders (2003). A History of Probability and Statistics and Their Applications before 1750. Hoboken, NJ: Wiley. ISBN 0471471291.
- Hald, Anders (1998). A History of Mathematical Statistics from 1750 to 1930. New York: Wiley. ISBN 0471179124.
- Kotz, S., Johnson, N.L. (1992,1992,1997). Breakthroughs in Statistics, Vols I,II,III. Springer ISBN 0-387-94037-5, ISBN 0-387-94039-1, ISBN 0-387-94989-5
- Pearson, Egon (1978). The History of Statistics in the 17th and 18th Centuries against the changing background of intellectual, scientific and religious thought (Lectures by Karl Pearson given at University College London during the academic sessions 1921-1933). New York: MacMillan Publishng Co., Inc.. pp. 744. ISBN 0028501209.
- Salsburg, David (2001). The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century. ISBN 0-7167-4106-7
- Stigler, Stephen M. (1990). The History of Statistics: The Measurement of Uncertainty before 1900. Belknap Press/Harvard University Press. ISBN 0-674-40341-X.
- Stigler, Stephen M. (1999) Statistics on the Table: The History of Statistical Concepts and Methods. Harvard University Press. ISBN 0-674-83601-4
- David, H. A. (1995). "First (?) Occurrence of Common Terms in Mathematical Statistics". The American Statistician 49 (2): 121–133. doi:10.2307/2684625. JSTOR 2684625.
External links
- JEHPS: Recent publications in the history of probability and statistics
- Electronic Journ@l for History of Probability and Statistics/Journ@l Electronique d'Histoire des Probabilités et de la Statistique
- Figures from the History of Probability and Statistics (Univ. of Southampton)
- Materials for the History of Statistics (Univ. of York)
- Probability and Statistics on the Earliest Uses Pages (Univ. of Southampton)
- Earliest Uses of Symbols in Probability and Statistics on Earliest Uses of Various Mathematical Symbols
- David Freedman (2002) (pdf). From Association to Causation: Some Remarks on the History of Statistics. University of California, Berkeley. http://www.stat.berkeley.edu/~census/521.pdf.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||